Reading a Document from the Database |
Back | Home | Next |
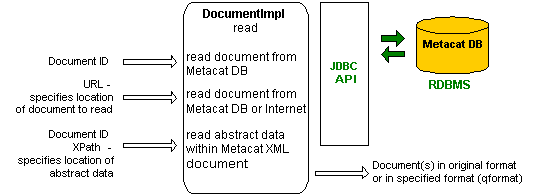
Metacat allows clients to read a document in several different ways, depending on how the client wants the document returned and how the client wants to specify the requested document.
The documents are requested by docid servlet parameter:
There are two different output formats that a client can request from
Metacat: HTML or XML. This is specified by the qformat parameter.
If more than one document is requested, the qformat does not matter,
instead the documents are zipped together and retrieved to the client.
When abstractpath parameter along with docid parameter is
specified as a XPath expression of the location of abstract data within
XML document, the abstract data only are read and retrieved in XML format.
For example, if a user wanted to request document NCEAS.54 and have it
returned as HTML, the servlet call would look like this:
http://server.domain.com/knb/servlet/metacat?action=read&qformat=html&docid=NCEAS.54
Another way to request a document is by Metacat URL. the URL would look like:
http://server.domain.com/knb/servlet/metacat?
action=read&qformat=xml&docid=metacat://server.domain.com/metacat?docid=NCEAS.54
Note that this url requests that the document be delivered in xml instead of html.
Metacat URLs as in the second example become useful when more than one Metacat server is being run at one site or a bunch of sites are replicating between each other and you want to specify a document at a precise location.