Bug #1132
closedfix access control rule ambiguities
0%
Description
We found some issues that need to be discussed regarding access control in the
EML2 specification. We have run into major problems while trying to implement
the specified access control procedures for Metacat and suspect that these
problems are not fixable without a change in the EML2 access control
specification. Though we are having these problems within Metacat, we believe
them to be general to any system that is trying to be EML2 compliant.
In EML2 there are two possible places where a processor may encounter access
control: one is at the resource level and the other is at the additionalMetadata
level. According to the EML spec, resource level access control applies to the
whole document and additionalMetadata rules apply to a specific subtree for
finer grained access control of EML subtrees. This allows one to have a general
access policy and then make specific exceptions or changes for particular subtrees.
The problems arise when a processor must remove a controlled subtree and
deliver it to the user. Once the user changes the document and
resubmits it, the subtree that was removed must be put back in its valid
and correct location.
1) Take this document for instance:
<a>
<b>b</b>
<d>d</d>
</a>
If a user has permission to write to the whole document (permission
comes from top level access control) and doesn't have permission to read
subtree d (restriction comes from addtionalmetadata access control) when
he tries to download the document he will get part of the document like:
<a>
<b>b</b>
</a>
The user adds the elements c and e to the document.
<a>
<b>b</b>
<c>c</c>
<e>e</e>
</a>
Once the document is submitted back to the processor, the processor must
figure out that element d (that was removed before) must fit in between c
and e like so:
<a>
<b>b</b>
<c>c</c>
<d>d</d>
<e>e</e>
</a>
This may seem simple, but first of all, the only way to know where d is
supposed to go when you remove it is to store its parent id and its most
immediate sibling(s) id(s). In this case d's parent is the same (a) but
in the original document b was it's most immediate sibling. If d is
inserted below b, the document becomes invalid. The only way to possibly
know where d is allowed to be reinserted is to parse the schema which
could still fail because element d could be legally allowed in many
different locations (ie, it is not necessarily deterministic wrt node placement).
2) Nested subtrees also present a problem.
<a id="100">
<b>
<c id="200">c</c>
<d>d</d>
</b>
</a>
An access module in additionalMetadata could specify that a user has read access
to c but not a. If the processor simply returns c but not a or sub-elements
(besides c) of a, the resulting document makes no sense. We need some sort of
cascade rule that says that once read has been taken away for a node, none of
its children can be made 'readable'.
3) Previously we stated that there are two palaces for access information to
exist. This is actually not quite correct. In EML2 each of the four resource
level modules (dataset, software, citation and protocol) have their own embedded
access module. Even though a document has only one resource level module, the
other resource level modules are embedded in each other. For example, you can
have a citation within a dataset. That citation has its own access module. We
have not defined in the EML spec how that is to be handled by a processor.
Should the top-level resource access description take precedence? Probably.
Should the lower level elements be ignored, or used in a manner similar to
additionalMetadata? If the latter, to what do they apply, themselves, or their
parent resource (unlike additionalMetadata, there is no describes element here
to clarify the situtation)?
Proposed solution:
Changing EML at this late date is hugely problematic. We feel that we should
maintain our commitment to make changes in EML backwards compatible (ie, EML
2.0.0 docs would be valid 2.0.1 docs). However, we feel that this is an
important bug that compromises the usefulness of EML, and so fixing it now is
the right thing to do. Nevertheless, we should minimize the disruptiveness of
the change by 1) trying not to change the schema structure, and 2) redefining
semantics of access control in a more tractable way.
We propose to alter EML to allow only two levels of access control. The first
would be document wide control, accomplished by a new "access" element on the
root "eml" document. The second would be data control for specific data files,
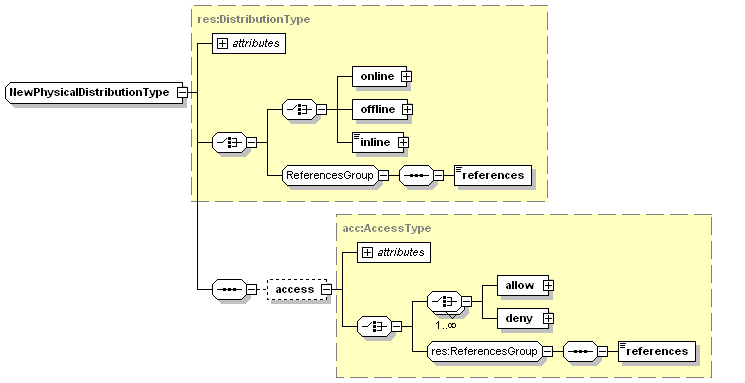
accomplished by an optional "access" element in the physical distribution module
that applies to the data object being described. We should remove access from
the eml-resource module (now that it is in the eml module itself), although this
would be an incompatible schema change. Alternatively we could simply define in
the spec that access elements on the "resource" module are to be ignored.
Restricting access control to the metadata and data respectively would greatly
simplify the processing of EML, although it would limit the granularity of
access control within the EML document.
Here's a fragment that shows what this new model might look like:
<eml>
...
<access>...</access> <-- defines overall access to
all metadata
...
<dataset>
<access>...</access> <-- this is ignored
<dataTable>
<physical>
<distribution>
<access>...</access> <-- defines access to the data object
in inline, online, or offline
elements (ie, not the metadata
itself, just the data)
<inline>...</inline>
</distribution>
</physical>
</dataTable>
</dataset>
</eml>
Of course, these changes would make an access element that is present in the
schema (under dataset, for example) be ignored. Which is certainly confusing.
We have to choose the lesser of two evils: 1) keep it and ignore it, which is
confusing but allows schema compatibility with 2.0.0, or 2) delete it, which is
clearer but makes all 2.0.0 documents that use it invalid and must be
transformed to become valid EML 2.0.1 documents. This is a tough choice.
We also need to clarify how to interpret the values found in the 'permission'
element, in that we should make it clear that 'changePermission' permission is
needed to change an access block, not just 'write' permission. Currently the
values we have (read, write, changePermission, all) are only tersely defined.
Comments or suggestions are welcome!
Jing, Chad, Matt, Dan, and Chris
Files
{kind=link}
{kind=link}
Related issues